Personalized federated learning is tasked with training machine learning models for multiple clients, each with its own data distribution.
The goal is to collaboratively train personalized models while accounting for the data disparity across clients and reducing communication costs.
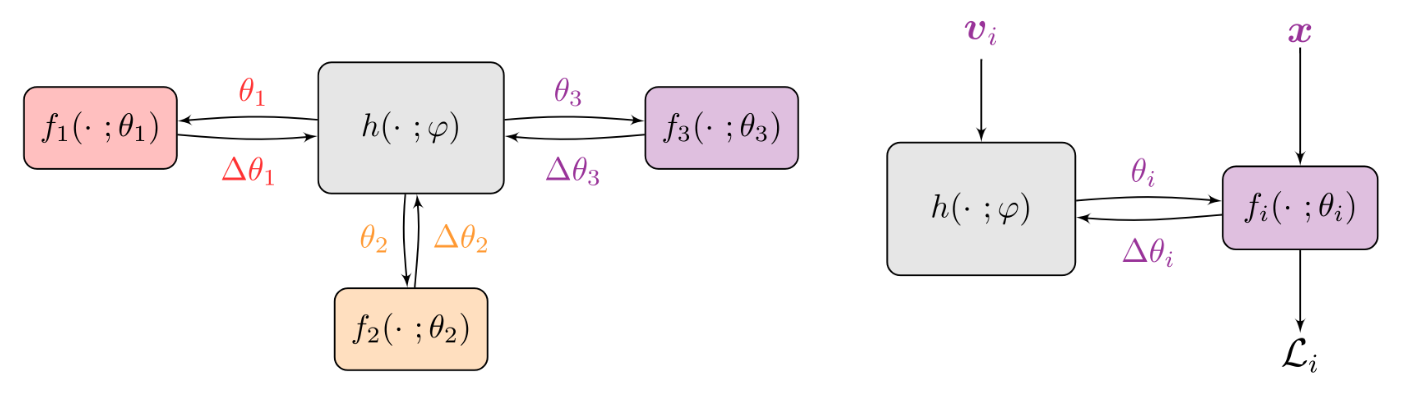
We propose a novel approach to handle this problem using hypernetworks, termed pFedHN for personalized Federated HyperNetworks. In this approach, a central hypernetwork model is trained to generate a set of models, one model for each client.
This architecture provides effective parameter-sharing across clients while maintaining the capacity to generate unique and diverse personal models.
Furthermore, since hypernetwork parameters are never transmitted, this approach decouples communication cost from the trainable model size.
We test pFedHN empirically in several personalized federated learning challenges and find that it outperforms previous methods.
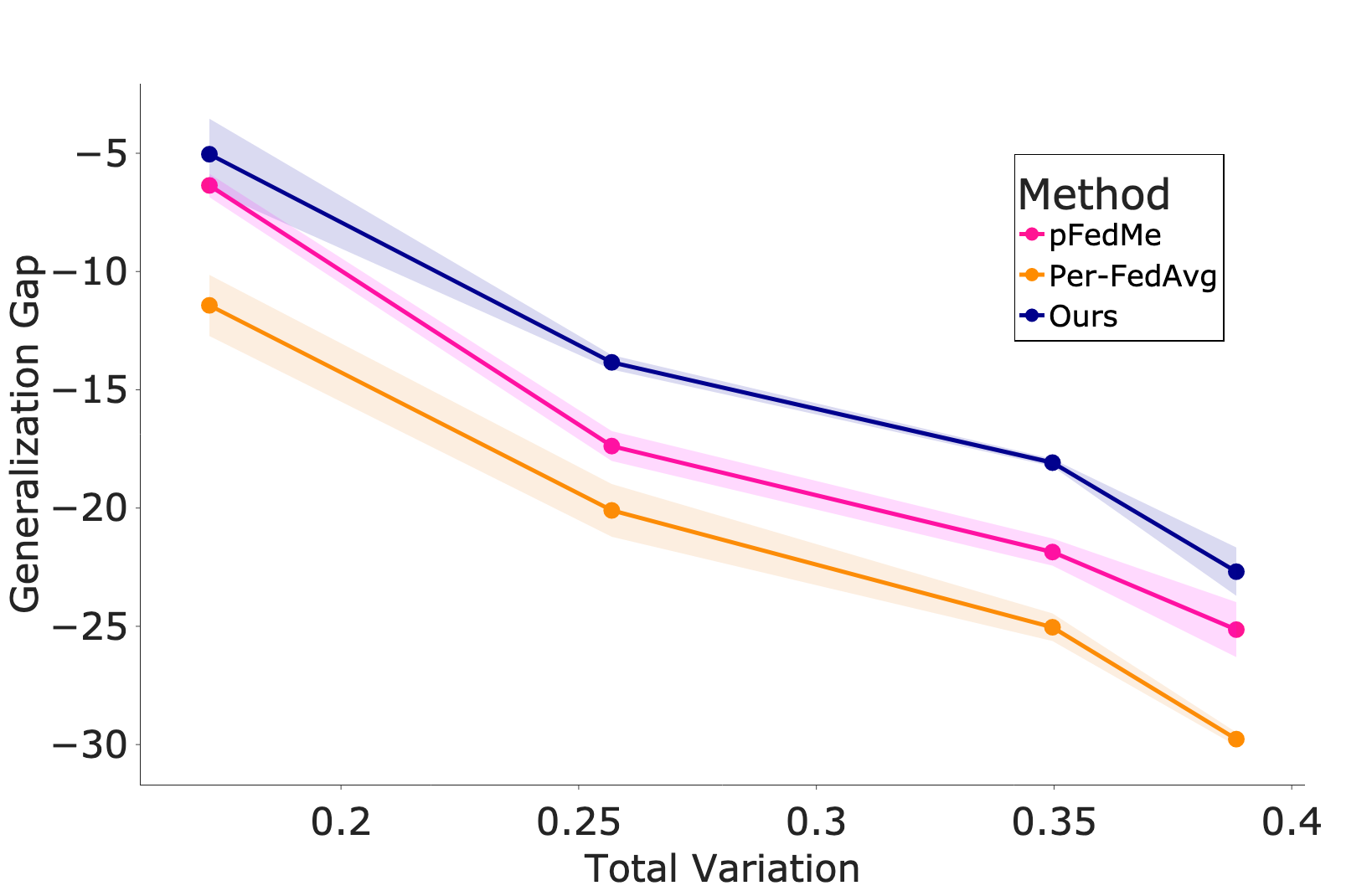
Finally, we show that pFedHN can generalize better to new clients whose distribution differ from any client observed during training.
Federated Learning
Federated learning (FL) aims to train a model over multiple disjoint local datasets. It is particularly useful when local data cannot be shared due to privacy, storage, or communication concerns. This is the case for instance, in IoT applications that create large amounts of data at edge devices, or with medical data that cannot be shared due to privacy. In federated learning, all clients collectively train a shared model without sharing data and while trying to minimize communication.
Personalized Federated Learning
One issue with FL is that training a single, global model cannot capture variability in the distribution of samples across clients. To handle this heterogeneity across clients, Federated Learning (PFL) allows each client to use a personalized model instead of a shared global model. The key challenge in PFL is to benefit from joint training while allowing each client to keep its own unique model and at the same time limit communication cost.
Personalized Federated Hypernetworks (pFedHN)
In this work, we propose using a single hypernetwok, termed Personalized Federated Hypernetworks (pFedHN), to learn personalized model for each client. PHN acts on client's embedding vector, that implicitly represents the data distribution of specific client, to produce the weights of a local network. In addition, we present pFedHN-PC ,a variant of pFedHN, that produces the feature extraction of the target network while learning a local classifier for each client. pFedHN and pFedHN-PC outperforms previous works in several FL setups and generalizes better to new clients with unseen data distributions.
Experiments
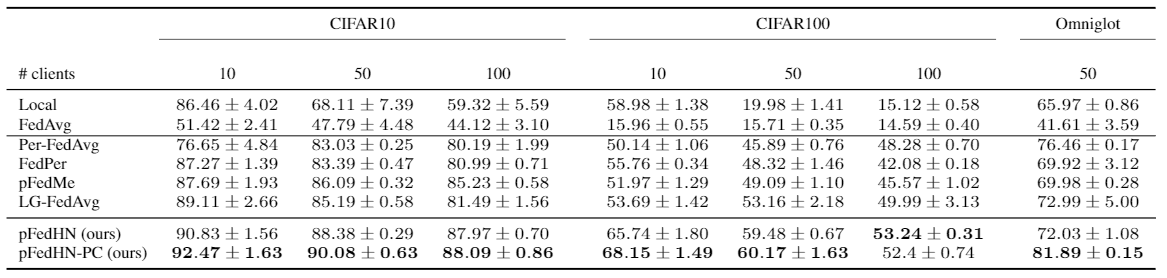
Heterogeneous Data
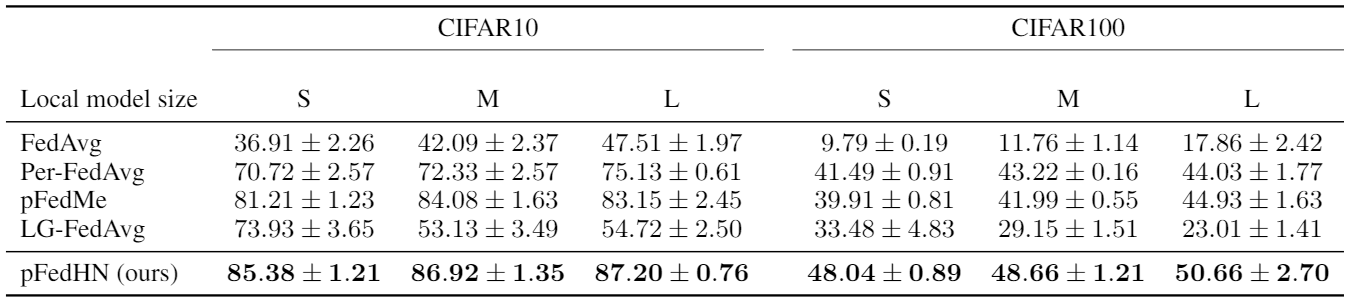
Computational Budget
Generalization to Novel Clients